
When data centre operators invest in UPS systems, it’s for one purpose only; to maximise power availability for their facility’s ICT equipment. A study [i] completed by the Ponemon Institute in 2013 makes this motivation easy to understand, as it showed how unplanned US data centre outages cost on average just over $7900 a minute.
If this sounds improbably high, consider the extent of the study’s coverage. This encompassed direct, indirect and opportunity costs from data centre outages, including damage to mission-critical data, the impact of downtime on organizational productivity, damage to equipment, legal and regulatory repercussions and lost confidence and trust among key stakeholders. The study used a year’s data from 67 data centres across various industry segments with a minimum footprint of 2,500 square feet.
So how do UPS manufacturers fulfil this critical availability requirement? In fact, the industry’s response has evolved steadily over the many years of its existence, by converting technological advances into UPS topology improvements. An apparently obvious starting point is to maximise UPS component reliability. However, while optimised reliability is certainly important, it has limitations as an availability solution. As ever more reliable – and costly – components are used, a law of diminishing returns starts to apply, until further increases in component costs fail to yield worthwhile improvements in the mean time between failures (MTBF).
Many of today’s UPS systems adopt a better approach, based on the fact that advances in technology allow a UPS system to be implemented as a set of manoeuvrable rack-mounting modules rather than as a single monolithic unit. To see why this is important, let’s start by looking more closely at availability; this depends on mean time to repair (MTTR) and MTBF, as expressed in the equation:
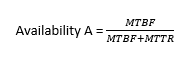
In other words, you can improve availability not only by increasing MTBF, but also by reducing MTTR.
Modular UPS designs exploit both opportunities; firstly, they increase MTBF by using redundancy, which creates fault tolerance. Consider a 120 kVA load, for example. This could be supported by a traditional, monolithic UPS, but if the UPS fails, power is immediately lost. Instead, though, the load could be supported by a modular configuration comprising four 40 kVA modules. Provided the UPS has a decentralised parallel architecture (DPA) with no shared static switch or single points of failure, it can continue fully supporting the load, without interruption, even if any one module fails. This is known as N+1 redundancy. For even greater MTBF, the number of redundant modules can be increased, making an N+n configuration.
Yet we have asserted above that reducing MTTR will also contribute towards improved availability. Monolithic systems had to be repaired in situ; an operation that could typically take up to six hours, while the UPS remains offline. By contrast, a modular system’s faulty module can be pulled out and replaced extremely quickly; the UPS can be put back online with the replacement module immediately and with minimised MTTR, while the faulty unit can be repaired away from the ICT installation and returned to backup stock.
The ultimate implementation of this concept comes with UPSs that offer ‘hot-swap’ capability. Hot-swap means that a faulty UPS module can be removed and replaced, all without shutting down or interrupting power to the load. Under these circumstances, MTTR dwindles to practically zero. This is why products like KOHLER Uninterruptible Power’s PW DPA 5000, for example, have a specified availability of 99.9999%, sometimes referred to as ‘six nines’ availability. This is a highly desirable quality for data centres in pursuit of zero downtime.
- [i] http://www.datacenterdynamics.com/content-tracks/power-cooling/one-minute-of-data-center-downtime-costs-us7900-on-average/83956.fullarticle


